* 크롤링 기초 - GET 요청과 응답 확인해 보기
# pip install requests
# pip install beautifulsoup4
- requests : GET, POST 등 HTTP 요청을 보내기 위한 라이브러리
- beautifulsoup4 : HTML 문서를 파싱하고 추출할 수 있는 라이브러리로, 웹 크롤링에 사용된다.
이 두 라이브러리를 설치하면, 파이썬 코드를 통해 웹 크롤링을 할 수 있다.
import requests
from bs4 import BeautifulSoup
req = requests.get(url) # GET 방식으로 네이버 URL에 요청
html = req.text # HTML 내용을 텍스트로 가져옴
print(html)
- request.get() : 네이버 서버에 GET 요청을 보내서 해당 페이지의 소스를 받아온다.
- req.text : 받은 응답의 본문을 텍스트로 변환하여 저장한다.
위 코드를 실행하면 네이버 웹페이지에 GET 요청을 보내고, HTML을 출력하는 간단한 웹 크롤링을 헤볼 수 있다.
 출력
출력
코드가 잘 동작하는 것 확인.
import requests
from bs4 import BeautifulSoup
req = requests.get(url)
print(req.request.headers) # 헤더 정보 출력
 출력
출력
내가 보낸 요청의 헤더 정보를 출력해 보았다.
이 정보는 내가 수정할 수 있다.
 F12
F12
import requests # 요청/응답 라이브러리
from bs4 import BeautifulSoup # HTML 파싱
# User-Agent 헤더 지정
headers = {
"User-Agent" : "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/128.0.0.0 Safari/537.36"
}
req = requests.get(url, headers=headers) # GET 방식으로 네이버 URL에 요청
print(req.request.headers)
 출력
출력
요청헤더의 User-Agent를 지정하고 다시 출력해 보니 내가 지정한 내용으로 바뀐 것을 확인할 수 있다.
* 네이버 검색 결과 크롤링
import requests
from bs4 import BeautifulSoup
keyword = input("검색어를 입력하세요: ")
url = base_url + keyword
print(url)
base_url에 검색페이지의 URL을 넣어줬다.
URL 마지막 부분의 query= 부분에 내가 입력한 검색어가 추가되어 검색 결과가 출력될 것이다.
 출력
출력
내가 입력한 검색어가 query= 뒤에 추가된 것을 확인할 수 있다.
 링크 접속
링크 접속
출력된 링크에 접속하면 페이지가 잘 뜨는 것을 확인할 수 있다.
* 네이버 뉴스 크롤링
 html 클래스 가져오기
html 클래스 가져오기
뉴스 검색 시 나오는 제목과 HTML 요소를 크롤링해 보겠다.
 class
class
news_tit 클래스명을 복사해 준다.
import requests
from bs4 import BeautifulSoup
keyword = input("검색어를 입력하세요: ")
url = base_url + keyword
print(url)
headers = {
"User-Agent" : "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/128.0.0.0 Safari/537.36"
}
req = requests.get(url, headers=headers)
html = req.text
soup = BeautifulSoup(html, "html.parser")
# 내가 가져온 class(class 앞에는 '.', id 앞은 '#')
result = soup.select(".news_tit")
print(result)
- result = soup.select(".news_tit") : news_tit 클래스를 가진 모든 요소를 선택.
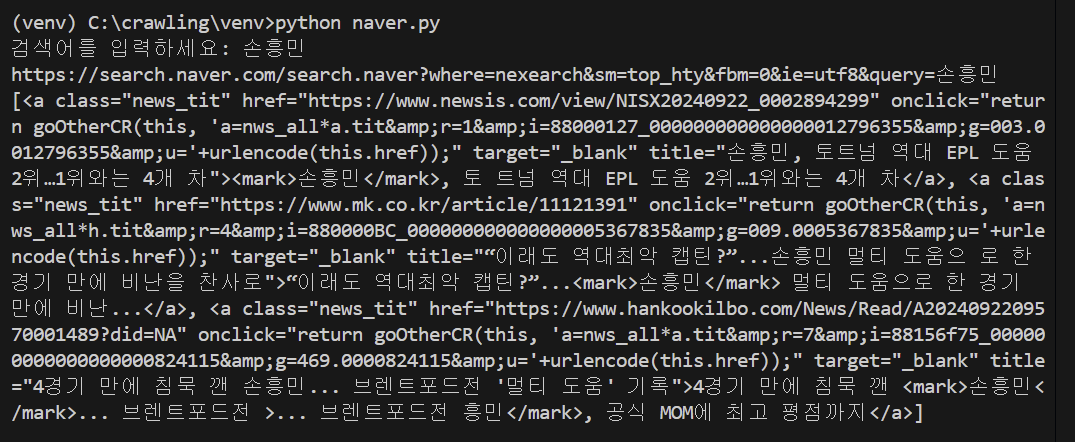 출력
출력
검색어 입력 시, 뉴스 제목과 HTML 요소가 출력되는 것을 확인할 수 있다.
import requests
from bs4 import BeautifulSoup
keyword = input("검색어를 입력하세요: ")
url = base_url + keyword
print(url)
headers = {
"User-Agent" : "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/128.0.0.0 Safari/537.36"
}
req = requests.get(url, headers=headers)
html = req.text
soup = BeautifulSoup(html, "html.parser")
# 내가 가져온 class(class 앞에는 '.', id 앞은 '#')
results = soup.select(".news_tit")
#출력
for result in results:
print(result)
print() # 줄바꿈
알아보기 쉽게 각 뉴스마다 줄 바꿈 하여 출력.
 출력
출력
각 뉴스마다 줄 바꿈 되어 잘 출력되었다.
import requests
from bs4 import BeautifulSoup
keyword = input("검색어를 입력하세요: ")
url = base_url + keyword
print(url)
headers = {
"User-Agent" : "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/128.0.0.0 Safari/537.36"
}
req = requests.get(url, headers=headers)
html = req.text
soup = BeautifulSoup(html, "html.parser")
results = soup.select(".news_tit")
#출력
for result in results:
print(result.text) # 제목만(텍스트만) 출력
print() # 줄바꿈
- print(result.text) : HTML 요소에서 텍스트만 추출하여 출력.
제목만 출력해 보기 위해 텍스트만 출력하도록 코드를 수정해 보았다.
 출력
출력
뉴스 제목만 출력되었다.
import requests
from bs4 import BeautifulSoup
keyword = input("검색어를 입력하세요: ")
url = base_url + keyword
print(url)
headers = {
"User-Agent" : "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/128.0.0.0 Safari/537.36"
}
req = requests.get(url, headers=headers)
html = req.text
soup = BeautifulSoup(html, "html.parser")
results = soup.select(".info.press") # 출처 class
#출력
for result in results:
print(result.text)
print()
뉴스의 출처를 출력해 보겠다. 뉴스 출처 부분에 해당하는 info press 클래스를 넣어주었다.
class 이름에 빈칸이 있으면 안 되기 때문에 '.'을 추가하여 info.press로 빈칸을 채워주었다.
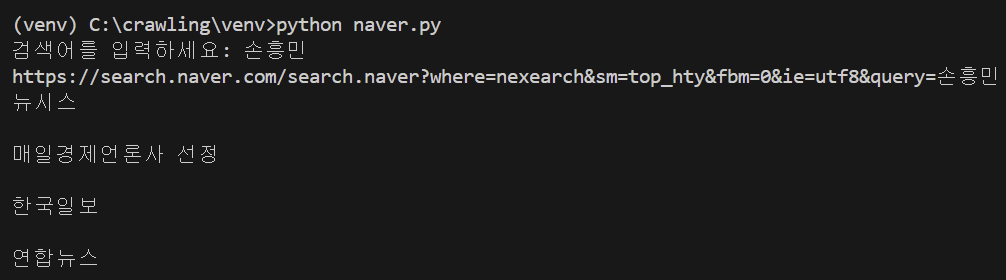 출력
출력
실습 끝.

댓글